Status
Video
Summary
The predominant purpose of this project is for the agent to go through a three-dimensional playing field with different themes of obstacles in each quarter of the map as it goes in a straight path to get to the finish line. This structure of the map is inspired by the battle royale-style game of Fall Guys. In the first sector, there are sets of poles or stacked blocks where the agent needs to learn to avoid as it moves forward and then it gets to a bridge with a river surrounding it where it needs to learn to cross the bridge. For this prototype, the agent is only able to move straight and turn left and right, as the obstacles will become more complicated and not particularly static, the jump functionality will be extended to the action list. The map is surrounded by glass walls where the agent needs to avoid touching in order to avoid negative reinforcement as the glass walls represent out of the map. The finish line is indicated at the end by the Redstone blocks where as soon as the agent arrives and touches it, a maximum reward is given and the game ends. The first prototype is a single agent game whereas in the future updates it is possibly going to be multi-agent. Currently, the benchmark for the single-agent is to avoid touching obstacles in order to maximize the reward when it arrives at the finish line.

Approach
For this prototype, we used the Deep Q-Learning Algorithm. Initially, we used the replay memory for training the DQN. It essentially stores the agent’s observed transitions in which it allows to reuse the data. Through random sampling, the transition that builds up a batch is decorrelated which will greatly improve the DQN training procedure. The purpose of the algorithm is to maximize the discounted cumulative reward. With Q-learning, by utilizing the given function:
And by taking the action in a given state, then a policy can be constructed as such to maximize the reward as shown below.
Since the information on the world is extremely limited and there is no access to the Q* , by utilizing convolutional neural networks as a function approximator we can construct one and train it to be similar Q* to. The Bellman equation given below is used as such that every Q* function for a policy obeys this equation.
The actions consists of the following:
1. Moving south (Forward)
2. Moving west (Left Horizontally)
3. Moving east (Right Horizontally)
The state space is the following:
[-10,10] x [1,40] = 840
Loss function:
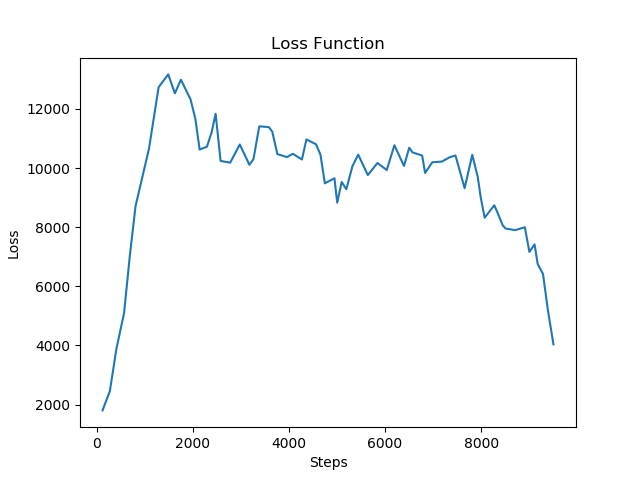
As mentioned above the purpose of Deep Q-learning is to find the Q function in order to construct a policy to maximize the necessary reward. For every epoch, the Q function gets updated by minimizing the loss function below which is essentially the difference between the two sides of the equality of the Bellman equation specified above, also known as the temporal difference error.
Reward Functions
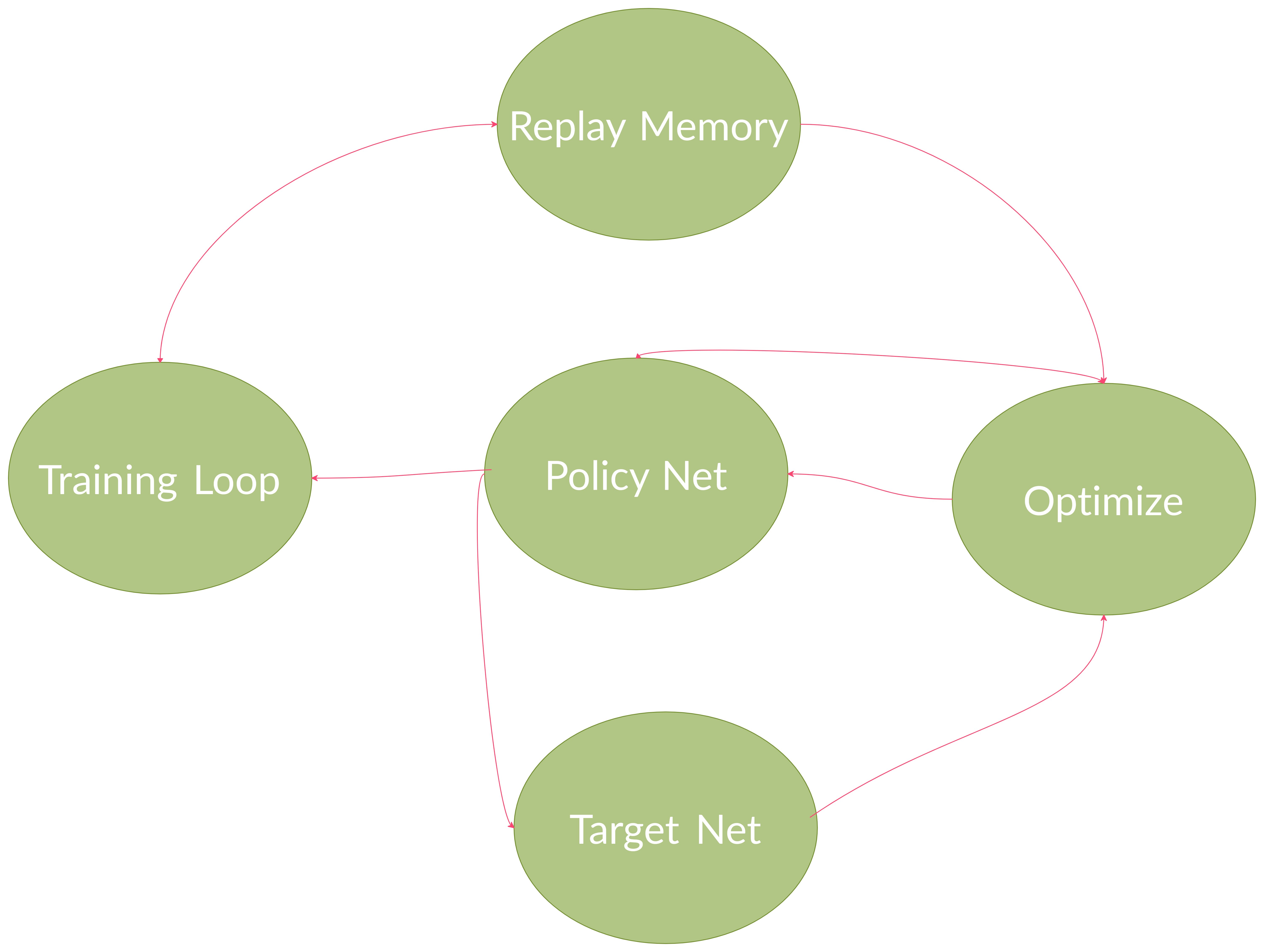
For the Q-network, the model will be a convolutional neural network that takes the observation tensor’s first index, and then it will output the action size. Essentially the network is attempting to predict the expected return of each specific action for the given input. In terms of deciding which action should be chosen, the epsilon greedy policy is implemented where partly the model chooses the action and sometimes the actions is chosen by random probability of starting with the hpyerparameter epsilon start and decaying toward epsilon end. Then epsilon decay hyperparameter is used to manage the rate. The following figure is a demonstration of the flow of the program where action chosen by random or epsilon greedy is an input to the Malmo environment where next is step is returned. The results are recorded in the replay memory and optimizatin is implemented on every iteration where random batches from replay memory are selected for the new policy training.
Evaluation
Qualitative
Since the goal of the agent is to make it to the end of the obstacle course with minimal collisions, and in the least number of steps, we can qualitatively see the agent learning as the episodes progress. In the first few episodes, the agent gets stuck a few times behind some obstacles, and is not able to make it to the redstone finish line within the specified max step limit. However after about 10 episodes it starts to make it to the end and achieves the highest reward of making it to the end. After which the agent seeks to minimize the steps, since each step is a slight penalty, to maximize overall reward and find the path that is most like a straight path to the finish line.
Quantitative
Below we can see the reward return graph chart. The goal of the agent is to make it to the end with minimal collisions with any of the obstacles. For each section in the obstacle course the agent is rewarded based on the amount of difficulty it is to reach past each threshold. The agent gets a penalty each time it hits an obstacle or goes off path. Furthermore, the agent is incentivized to reach the redstone finish line, due to the finish line having the highest reward of any threshold. We have also made progression forward a lot faster in terms of steps for each in the action dictionary, so the agent would progress forward more than anything else. The reward chart above details how the agent learns as the episodes progress. We can see that after a while in training the agent's return goes down, this can perhaps be due to the neural network overtraining and learning specific patterns and not being general enough for different randomly general obstacle courses.
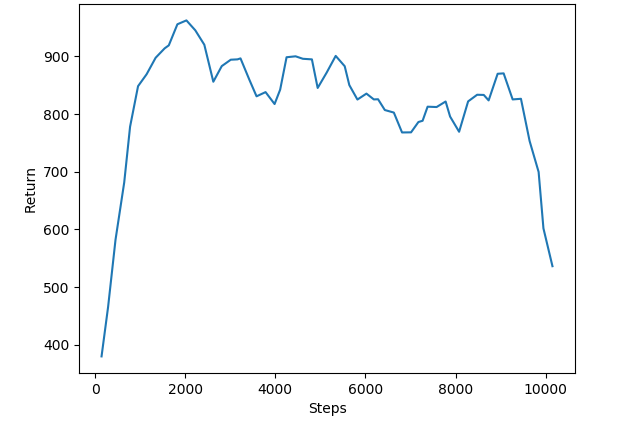
Later we adjusted the reward system for the agent. We removed any reward for moving forwards, instead changing to there being a penalty for being for each step taken. We then set the rewards for each subsection to be 100, and 150, bringing them a lot closer together. We then set the penalty for going into the water to -10 and for hitting any obstacle to -1. After implementing these changes we then restrained our model and were pleased with the results. We began to see the rewards increase constantly and not decrease and training went on beyond a certain threshold. Below is the reward graph for the newly trained agent.
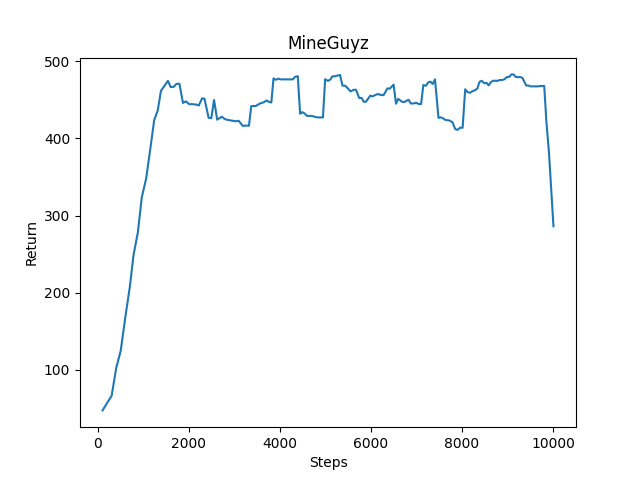
For this training attempt we also graphed the episode loss and we can see that it consistently began to converge towards 0 and the steps went towards positive infinity.